오늘 우리 상품들 네이버 최저가 조사하고, 경쟁사 상품 판매 가격대도 조사해서 보고해줘
혹시 오늘 '야근'을 계획하고 있나요? 이런 업무를 위해서는 보통 직접 검색해서, 검색 결과들을 눈으로 확인하고, 엑셀파일에 하나씩 정보를 옮기면서 진행합니다. 하지만, 이렇게 일한다면 너무나 많은 시간이 걸릴 수 있습니다.
조금 더 스마트하고 효율적인 방법이 있다면, 충분히 시간을 써서라도 더 나은 방법을 사용하는 것이 좋겠습니다. 그 방법을 사용하기 위해 조금의 노력이 필요해도 말이죠.
이번 글에서는 '웹 크롤링(Web Crawling)'에 대해 알아보겠습니다. 웹 크롤링에 대해 들어 보신적 있으신가요?

웹 크롤링이란?
웹 크롤링은 웹 페이지들을 탐색하여 테이터를 '자동'으로 수집하기 위한 방법으로, Application을 이용해 웹 프로토콜(http, https)로 URL에 접근하여 자동으로 웹 문서를 탐색하는 것입니다. 이 과정에서 크롤러(또는 스파이더)라고 불리는 자동화된 프로그램을 사용하기도 합니다.
인터넷에 존재하는 방대한 양의 정보를 사람이 일일이 파악하는 것은 비효율적일 때가 많고, 특히 이런 일을 반복적으로 해야하는 경우에는 사람이 직접 하지 않는 다른 방법을 고심해볼 필요가 있습니다. 웹 크롤러는 규칙에 따라 자동으로 웹 문서를 탐색하는 컴퓨터 프로그램입니다.
웹 크롤링의 활용
웹 크롤링은 다양한 분야에서 활용될 수 있습니다. 예를 들어, 검색 엔진 최적화(SEO) 분석, 시장 조사, 데이터 분석 등에서 유용합니다. 특히 대량의 데이터를 신속하게 수집해야 할 때 큰 역할을 합니다. 소셜 미디어 분석, 경쟁사 분석, 고객 의견 수집 등 다양한 목적으로도 사용이 가능합니다. 그리고 웹 크롤링을 통해 얻은 데이터는 비즈니스 인사이트 도출, 트렌드 분석, 의사 결정 과정에서 중ㅇ한 근거 자료로 활용될 수 있습니다.
다만, 모든 웹사이트가 크롤링을 허용한 것이 아니기에, 합법적으로 이요하는 것이 중요합니다. 크롤링은 목적 서버에 과도한 부하를 주지 않는 범위에서 수행해야 되고, 상업적 목적의 크롤링의 경우 정보 제공자에게 허락을 받아야 합니다. 대부분의 웹사이트의 경우 최상위 페이지에 bot에 대한 정책을 명시하고 있습니다.
robots.txt 파일
User-agent : robots.txt의 정책을 지켜야 하는 대상
Allow : 자동화 페이지가 허용된 부분을 명시
Disallow : 자동화 프로그램의 접근이 허용되지 않는 부분을 명시
'/'는 모든 페이지, '/$'는 첫 페이지를 말함
<예시1> 모든 문서에 대한 접근을 허가한다는 내용
User-agent: *
Allow: /
<예시2> 모든 문서에 대한 접근을 차단하고, 첫 페이지만 허가한다는 내용
User-agent: *
Disallow: /
Allow: /$

웹 크롤링에 필요한 기술
웹 브라우저를 이용하여 받은 데이터는 HTML/CSS 형태로 제공되기 때문에, 웹 크롤링을 위해서는 HTML과 CSS, JavaScript의 기본적인 이해가 필요합니다. 또한, HTTP 요청과 응답의 이해도 중요합니다. 웹 크롤링 과정에서는 웹 페이지에서 데이터를 추출하는 과정이 포함되므로, 웹 페이지의 구조를 파악하고, 원하는 데이터를 정확하게 추출하기 위해 이러한 웹 기술에 대한 이해가 필수적입니다.
파이썬과 웹 크롤링
파이썬은 웹 크롤링을 위한 다양한 라이브러리를 제공합니다. 대표적으로 BeautifulSoup, Scrapy, Selenium 등이 있으며, 이들을 활용하면 손쉽게 웹 크롤링을 수행할 수 있습니다. 파이썬의 이해하기 쉬운 문법은 웹 크롤링을 처음 시작하는 사람들에게도 큰 장점이 됩니다.
크롤링의 방법
정적 크롤링
정적 크롤링은 브라우저를 통하지 않고, 웹 프로토콜을 이용해 Application이 직접 웹 페이지의 HTML을 그대로 가져와서 필요한 데이터를 추출하는 방식입니다. 이 방식은 웹 페이지의 구조가 변경되지 않는 한 매우 효율적이고 간단합니다.
- BeautifulSoup 사용: Python의 BeautifulSoup 라이브러리를 사용하여 HTML 문서에서 데이터를 추출할 수 있습니다.
find와 find_all 함수를 사용하여 특정 태그나 클래스에 해당하는 내용을 쉽게 찾을 수 있습니다. - 정적 페이지의 특징: 정적 웹 페이지는 사용자의 요청에 따라 내용이 변경되지 않으며, 서버에서는 사용자에게 동일한 HTML 파일을 전송합니다. 이러한 특성 때문에 정적 크롤링은 웹 페이지의 구조만 이해하면 비교적 쉽게 데이터를 추출할 수 있습니다. 다만, 웹 주소에 해당하는 페이지가 변경 또는 삭제될 경우 수집 코드를 다시 작성해야 합니다.
동적 크롤링
동적 크롤링은 웹 페이지가 사용자의 상호작용에 따라 동적으로 데이터를 생성하고 변경할 때 사용하는 방식입니다. 주로 자바스크립트를 통해 데이터가 로드되는 경우에 필요합니다.
- Selenium 사용: 동적 웹 페이지의 경우, Selenium 같은 도구를 사용하여 웹 브라우저를 자동으로 제어하고, 페이지가 완전히 로드된 후 데이터를 추출할 수 있습니다. Selenium은 웹 브라우저의 동작을 자동화하여 동적으로 생성되는 데이터에 접근할 수 있게 해줍니다.
- 동적 페이지의 특징: 동적 웹 페이지는 사용자의 입력이나 상호작용에 따라 내용이 변경됩니다. 예를 들어, 스크롤을 내리거나 버튼을 클릭할 때 새로운 데이터가 로드되는 경우가 이에 해당합니다. 이러한 페이지에서 데이터를 추출하기 위해서는 페이지의 동적인 행위를 모방할 수 있는 도구가 필요합니다.
정적 크롤링 맛보기
1. DOM(Document Object Model) 파악하기
문서 객체 모델이라는 뜻으로, XML 또는 HTML의 요소에 접근하는 구조를 나타냅니다. DOM은 문서의 구조화된 표현을 제공하여 프로그래밍 언어가 문서 구조에 접근할 수 있는 방법을 제공합니다.
2. BeautifulSoup의 find() 함수로 요소 접근하기
DOM을 파악하지 않고, 전체 문서에 조건에 맞는 태그 및 요소 값을 검색합니다.
조건에 부합하는 요소를 하나만 검색하고, 여러 개의 요소가 있을 경우 가장 앞에 위치한 요소를 반홥합니다.
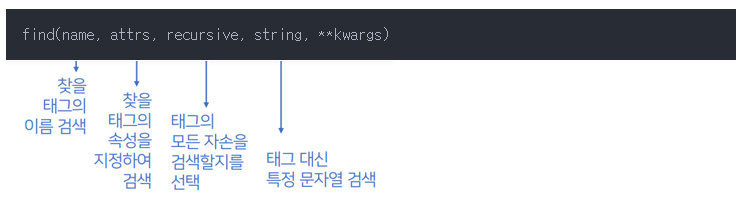
이와 달리, find_all() 함수는 원하는 태그를 모두 찾아서 리스트 형태로 저장하여 리턴해줍니다. 검색된 요소가 여러 개일 경우에는 find_all() 함수를 사용하며, 함수의 매개변수는 find() 함수와 동일합니다.
또는 CSS 선택자를 매개변수로 받는 select() 함수를 사용해서 크롤링을 할 수도 있습니다. find() 함수 사용보다 더욱 정교하게 데이터 추출이 가능합니다.
위 설명된 함수들을 사용하는 예시는 각 함수를 인터넷에서 검색해보면 쉽게 찾아볼 수 있습니다. 그리고 웹 크롤링과 관련된 코드를 검색해서 예제를 따라 해보고, 또는 간단한 웹 크롤링을 실행하는 것을 반복하면서 원하는 데이터를 효율적으로 수집해 보시기 바랍니다.